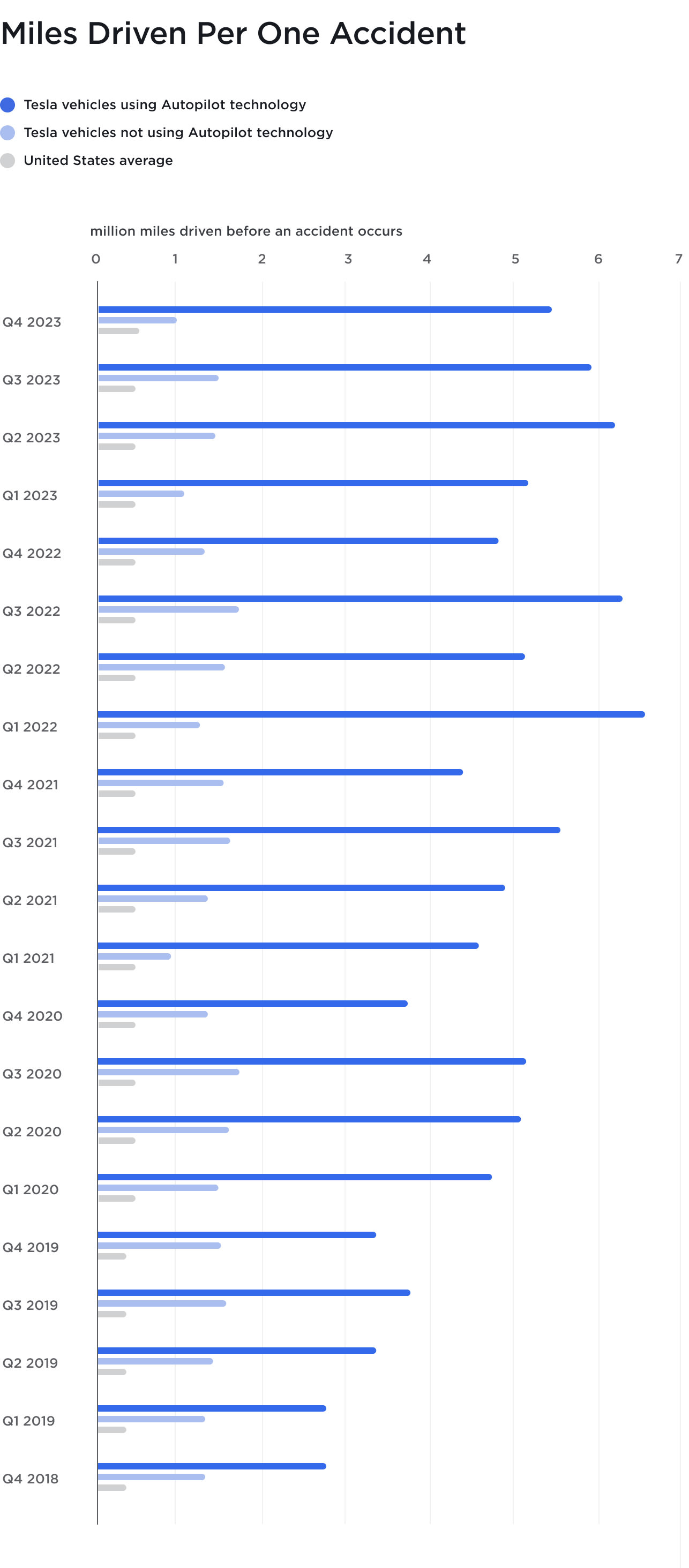
One thing I hate about Musk saying things like "They have fewer accidents than people" is that it is only able to be engaged in the easiest of scenarios. So per mile, self driving on the easiest roads barely has less accidents than a human in adverse conditions?
That doesn't seem to actually be better than people yet.
This is all miles traveled, but clever data analysis uses aggregate data as they've done here. It's not "lying" in that the vast majority of miles are traveled on the highway instead of on city streets or even suburban access roads.
Also note:
> To ensure our statistics are conservative, we count any crash in which Autopilot was deactivated within 5 seconds before impact, and we count all crashes in which the incident alert indicated an airbag or other active restraint deployed. (Our crash statistics are not based on sample data sets or estimates.)
Of course, Tesla's official guidance in-car via warning messages is that Autopilot is not safe for city streets, only highways, so technically it shouldn't be used on pedestrian-adorned streets anyways.
It's important for metrics to be measurable. Throwing in a bunch of subjective criteria like how tricky a road is will only make the analysis less meaningful.
Yes, it's important to understand the limitations of the metrics, but the existence of limitations doesn't mean that the metrics should be thrown out entirely.
Measuring metrics that are easy to measure doesn't help if the metric doesn't mean anything.
Comparing collision rates between human drivers in all conditions and Tesla automation in conditions where it allows activation and is activated is simply not a usable comparison.
Certainly, there's not an easy way to measure the collision rate for all humans all cars in only the conditions where Tesla automation can be activated, and that makes it hard to find a metric we can use, but that doesn't mean we have to accept an unusable metric that's easy to measure.
But if you are like Tesla and can not even be bothered to put in a methodology section... or any analysis... or any data... really anything other than a soundbite conclusion then maybe you should not get a free pass on driving vehicles when you only demonstrate a level of safety analysis unfit for even a grade school science fair.
The issue is that it isn't safer, seemingly under any conditions. If it had lower accident rate per mile, that the stat for humans includes adverse conditions while the stat for tesla only includes ideal conditions. Presumably humans are safer than their average on highways...
Only engaged on the easiest of roads? I haven't been on a road my tesla wouldn't enable lol WTF are you talking about, shit mine works in pooring rain, it complains but drives fine.
There's a fascinating relationship between tail recursion and continuations, because any non-tail-recursive function call can in principle be made tail-recursive through conversion to explicit continuation-passing style.
For added fun, that continuation can then be defunctionalized [1] back into a data structure. It can be argued that TRMC as implemented in the linked post is simply a special case of this more general transformation.
> because any non-tail-recursive function call can in principle be made tail-recursive through conversion to explicit continuation-passing style.
I mean, the call stack is literally just a convention for storing continuation state. The C standard describes the effect of calling another function "suspend[ing]" execution of the current function.[1] What differentiates CPS from regular recursive programming is that this behavior isn't maximally transparent, and typically is also less efficient in machine code.
All of these modes of behavior were mostly well understood early on, but it took several years for the literature to rigorously distinguish and define them, and then complete the circle by declaring equivalencies that nobody ever seriously doubted in the first place.
The upshot is we're like in the 4rd or 5th cycle of people rediscovering things like asynchronous programming. During previous epochs people just beefed over different but functionally similar terminology: e.g. interrupts vs polling (in that case, a carry over from hardware terminology). Unix's awkward signals and then threading APIs being a legacy of those (not very distant) debates. One of the first battles was whether to build recursion into languages atall, rather than requiring explicit management of call state, relying on global space for the fast path that didn't require recursion. Today the dispute is CPS vs blocking, but it's the same basic dichotomy and arguably we're just rehashing the same battle over again, without even changing the terminology.
The blocking/polling/recursion camp seems to invariably win out. The whole purpose of general purpose programming languages is to hide basic code flow management, particularly call state, behind an abstraction, and in the vast majority of code written in these languages, even highly concurrent code, such state bookkeeping is obnoxious noise when it leaks through too heavily. It's ironic when some language aficionados (Rust, Javascript, etc) justify it by saying it's about maximizing performance or making things explicit, ignoring the fact that almost all of this "efficient" and "transparent" code is running within a process (also variously described as "threads" and "coroutines" in bygone eras) isolated with hardware-supported virtual memory, all of which are predicated on transparent, blocking behavior. IOW, preferences have already been established and then punctuated multiple times, now we're just haggling over the finer details.
[1] C11 6.2.4p6: "... Entering an enclosed block or calling a function suspends, but does not end, execution of the current block...."
Cool, I had heard of defunctionalizing CPS before but never dared to try it.
I tried to follow along defunctionalizing map, but it is a bit different since it has a return value, whereas in the video it is a void. What I ended up with was equivalent to building a list and then reversing it. So it did infact work (all functions were tail callable). This was mentioned in the article as inferior to the author's final product though. So I think it is a bit different to a special case of CPS defunctionalization optimization.
Although there may have been other ways to deal with the return value in continuations...
> any non-tail-recursive function call can in principle be made tail-recursive through conversion to explicit continuation-passing style
This sounds great, but in the end you just construct your own call stack under the guise of chaining continuations together.
The real optimization happens when the continuations have structure, so that you can merge the composition of multiple continuations into one. And once you represent the continuation with its data, you just get "accumulator-passing style".
According to the article, PHP can handle other encodings by just treating sequences of strings as byte sequences and not caring what the encoding is. There example:
$string = "漢字";
But if you are using say UTF-8 and one of those Chinese characters has one of its bytes have a value of 34 (the ascii value of "), then wouldn't the string terminate prematurely?
Edit: to answer my own question, quote from wikipedia: ASCII bytes do not occur when encoding non-ASCII code points into UTF-8
Also, the compiler might be treating the input file as UTF-8, while the semantics of the language may treat string literals as the sequence of bytes when encoded as UTF-8.
These channels are immoral and against YT's TOS. YT should take them down, but they haven't (yet).
Something I could do about it is personally is stop using YT until they do. I've seen other instances of the negatives of YT that are making me think this is what it must come to (i.e. https://news.ycombinator.com/item?id=24571038).
The ironic thing is that I'm tempted not to ban YT because there's so much content that I like (pbs spacetime, veritasium, etc). However this type of reasoning is how atrocities in the past have been allowed to happen. Essentially youtube is Google's real monopoly and this is just another example of the problem of monopolies.
So I'm going to block myself from youtube (since habit is too hard to break, I'll do it by adding these lines to /etc/hosts)
127.0.0.1 youtube.com
127.0.0.1 www.youtube.com
Could someone please post here when these channels are deleted?
There's an equally annoying problem in software engineering at large corporations (aka Google), where hundreds of services you need to know about are named with some cute name that gives you no idea what the thing actually is.
For AWS, there's a website called "AWS in Plain English" that explain what each service does. For instance, it's pretty hard to guess what AWS Route53 does unless you've come across it elsewhere.
I guess. I wanted to know what kind of corporate wiki / database is a good choice for storing / retrieving human-readable, verbose information about servers or services.
My current employer uses atlassian confluence for that. So if you don't know what is this server "potato1" with 7 docker containers for, you can type "potato1" in confluence and hopefully get an answer.
Maybe in big companies they use homebrew solutions for this
Link to source? Current data on cdc is 1,920,904 cases and 109,901 deaths which is 5.7% (and it doesn't appear to be changing much). That's about 20 times higher than your figure of 0.3%.
Just to those who downvote - if someone poses a question or argument which you think is easily refuted, by downvoting or removing that question you remove the opportunity for anyone else with the same argument to learn something.
And maybe this is part of the problem with the whole covid discussion - labeling all these simple arguments from all sides as "wot a moron!" instead of presenting them clearly for people to learn from.
This is the amount of confirmed people that tested positive with Covid, not even including once that were discovered with anti-bodies. CDC has mathematical models to predict the actual death rate:
https://www.usatoday.com/story/news/factcheck/2020/06/05/fac...
{kind=link}